화이트 모드로 보시길 권장합니다
[A.아이 Project] 시리즈는 Ai를 이용해 친족간 특징을 분석하여
미아와 부모를 매칭시켜주는 서비스 개발 일지이다.
' A.아이 '란 무엇인가?
' A.아이 '란
' A.아이( Ai 아이 찾기 ) '란 인공지능을 이용해 친족 간 유전적 특징을 분석하고, 실종아동의 인적사항을 바탕으로 친족 관계일 확률이 가장 높은 사용자를 찾아 매칭을 통해 실종아동의 가족을 찾아주는 것을 목표로 한다.
한국에서는 실종아동을 찾을 때, 직접 조사, 실종아동의 정보 공개를 통한 시민들로부터의 신고를 받는 방식을 사용하며, 해외의 경우 어린이집 아이들의 얼굴을 미리 인공지능에 등록해 둔 후, 어린이집 아이 실종 사고 발생 시 빠르게 대처하는 방식의 서비스가 존재하며 이러한 서비스들은 최근 실종아동에 초점을 두고 있다.
' A.아이 '는 장기실종아동에 초점을 두고 있다.
본 문서는 A.아이 서비스의 기획 및 개발 자료로서, 해당 서비스의 아이디어, 콘텐츠 및 관련 정보는 저작권 및 기타 지식재산권 보호를 받습니다.
본 문서의 전체 또는 일부를 제3자에게 제공하거나 공유하는 경우, 본 아이디어 및 내용을 개인적인 목적(예: 별도의 사업화, 재판매, 유사 서비스 개발 등)으로 사용할 수 없습니다. 해당 자료는 정보 제공 및 검토 목적에 한하여 공유되며, 본 문서의 무단 복제, 수정, 배포, 상업적 이용은 엄격히 금지됩니다.
이를 위반할 경우 법적 책임이 발생할 수 있습니다.
' A.아이 ' 아이디어의 대격변
서비스 대격변의 이유
서비스가 바뀐 이유
본래의 ' A.아이( Ai 아이 찾기 ) '는 위에서 말한것과 같이 인공지능을 이용해 서비스에 등록된 사람들의 얼굴 이미지를 비교한 후, 가장 얼굴이 유사한 두 사람을 매칭하여 주는 서비스이다.
이 서비스는 가족을 찾고자 하는 사람들이 사용을 하기에 서비스에 등록된 사용자중 얼굴이 유사한 사람이 있다면 둘이 가족일 확률이 높을 것이라고 생각했기에 이러한 서비스를 기획하였었다.
하지만 아이디어를 곱씹어 보다 보니 아이디어에 결함이 너무나도 많이 보였기에 아이디어를 수정하게 되었다.
우선 사용자들의 얼굴을 비교하여 가장 유사도가 높은 두 사람이 가족일 것이라 예측하는 부분이 서비스를 상용화 하기에는 무리가 있다고 판단한것이 아이디어를 수정한 가장 큰 이유였다.
서비스 대격변
서비스 배경
배경
최근 핸드폰으로 오는 안전 안내 문자를 보면 '서울경찰청'과 '경기도청'에서 실종 인물을 찾는 문자가 매주 약 5건씩 오며 매주 실종 사건이 발생한다는 점에서 실종아동에 대한 관심이 생기게 되어 관련 자료를 찾아보게 되었다.
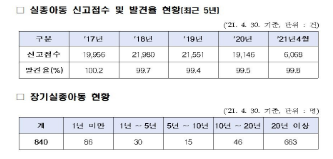
보건복지부 통계에 따르면 2018년부터 2021년까지 매년 약 2만건의 실종아동이 발생한다고 하며 1년이 넘도록 집으로 돌아가지 못한 장기실종아동은 2021년 4월 기준 871명으로 절대 적지 않은 숫자였다.
2020년 CU와 아동권리보장원이 함께한 '실종아동 찾기 캠페인'을 통해 본인이 실종아동인지 모른채 살아가던 '강씨'를 찾을 수 있었다. 우연한 기회로 자신의 어린시절 사진이 CU에서 실종아동으로 송출되고 있는것을 발견한 후, 아동권리 보장원에 문의하게 되면서 20년만에 가족과 재회할 수 있었다고 하며, 파이낸셜뉴스 기사에 나온 '김세근'씨의 경우 어렸을적 가족을 잃어버리게 되어 본인의 정확한 이름, 나이를 모른다고 한다. 이를 통해 너무 어렸을때 가족을 잃어버려 본인의 이름등을 기억하지 못하는 경우가 존재한다는 것을 알수 있었다.
실종아동의 신원을 빠르게 파악하여 신속하게 가족의 품으로 돌아갈 수 있게 해주는 '지문등 사전등록' 서비스는 어린이 지문 사전등록률이 55.8%로 실종아동 10명중 5명은 지문이 등록되어 있지 않았다. 이는 지문을 등록하기 위해선 경찰서, 지구대 등을 방문해야 하는 번거로움이 있기 때문이라는 개인적인 생각이 들었다.
위 문제들을 해결하는데 도움이 되고자 저희 팀은 실종아동 예방 서비스를 구상하게 되었다.
서비스 개념
보호자의 보호가 필요한 아동, 치매 어르신, 지적·자폐성·정신장애인 등 이하 '아이'라 칭한다.
'A.아이'는 실종아동 예방 서비스로 실종아동의 신원파악을 돕기 위한 얼굴인식인공지능 서비스이다.
집에서 간편하게 아이의 얼굴을 등록시켜 실종발생시 빠른 대처가 가능토록한다.
보호자가 확인되지 않는 아이를 발견후 아이의 신원 확인이 어려울 때 아이가 실종아동으로 등록되어 있는지 아이의 얼굴 사진을 통해 검사가 가능하다.
보호자가 확인되지 않는 아이를 발견후 아이의 신원 확인이 어려울 때 아이가 실종아동으로 등록되어 있는지 아이의 얼굴 사진을 통해 검사가 가능하다.
본인이 실종아동인지도 모른채 살아가던 분들이 이 서비스를 통해 본인이 실종아동으로 등록되어 있진 않을지 실종아동들의 얼굴을 학습한 모델이 사용자의 현재 혹은 어릴적 사진을 이용해 검사해 주는 서비스이다.
사용자들이 들록한 얼굴 이미지를 인공지능 모델에 학습시켜 얼굴 사진만으로 사진속 인물의 신원을 파악할 수 있도록 한다.
서비스에서 사용되는 얼굴인식 인공지능 모델은 사용자들이 사전에 등록한 얼굴 사진과 '안전Dream'의 OpenApi가 제공하는 실종아동들의 이미지로 실종아동들의 얼굴을 학습시킨 후, 사진속 인물이 실종아동으로 등록되어 있는지 판단한다.
주요 타겟 고객
아이의 얼굴을 사전에 등록하여 혹시 모를 실종상황에 대비하고자 하는 보호자 등의 사람들.
- 기존에 있는 지문 사전등록 서비스의 경우 경찰서를 방문해야 하는 번거로움이 있다.
- 집에서 간편하게 아이의 얼굴을 등록하여 실종 발생시 빠른 대처가 가능하게 할 수 있다.
실종아동 발견 후 신원을 파악해야 하지만 어려움을 겪고 있는 경찰 등의 사람들.
- 지문이 등록되어 있지 않은 실종아동은 발견후 신원을 확인하는데 까지 평균 56시간이 걸린다.
- 하지만 이 서비스를 이용할 경우 아동의 얼굴 사진만으로 쉽게 신원 확인이 가능하다.
- ex. ) 보호자가 확인되지 않는 아이의 신원을 파악하고자 지문 확인을 해 보았지만 등록이 되어있 지 않아 신원 파악이 어려울 때.
본인이 실종아동인지 검사 하고싶어 하는 사람들.
- 어린 시절부터 아동 보호 시설에서 자란 사람들.
- 어린 시절부터 아동보호 시설에서 자라며 실종아동 전문센터에서 본인이 등록되어 있는지 확인해 보고 싶지만 어릴적 원래 이름을 기억하지 못하는 사람들.
주요 서비스 내용
주요 서비스 기능
- 우리아이 얼굴 사전등록 서비스
- 아이의 얼굴을 사전에 등록해 실종발생시 빠른 대처가 가능하도록 하는 기능
- 얼굴을 등록하기 전, 아동의 얼굴 사진 수집 동의, 아동의 보호자 개인정보 수집 동의, 개인정보 제 3자 제공 동의를 받아야 한다.
- 집에서 간편하게 아이의 얼굴 사진을 촬영하는 것으로 얼굴 등록이 가능하며 얼굴과 함께 아이의 구체적인 정보( 나이, 이름, 보호자명, 보호자 연락처 등 )를 등록 할 수 있다.
- 아이의 얼굴을 사전에 등록해 실종발생시 빠른 대처가 가능하도록 하는 기능
- 실종아동 검색 서비스
- ' 안전Dream '에서 제공하는 ' 실종검색 OpenApi '를 이용해 이름, 실종 발생일 등으로 실종아동 검색이 가능하다. 이때 검색된 실종아동의 이름, 성별, 사진, 실종 발생일, 실종 당시 나이, 현재 나이, 신체적 특징, 실종 발생 장소에 대한 정보를 사용자에게 제공한다.
- 검색시 기본적으로 실종아동의 이름, 성별을 입력받으며 부가적 으로 실종 발생일, 실종 당시 나이, 현재 나이, 신체적 특징, 실종 장소를 입력받는다.
- 실종아동 신원확인 서비스
- 사용자의 얼굴이 사전에 등록되어 있는지 혹은 실종아동으로 등록되어 있는지 얼굴 사진을 이용해 검새주는 서비스로 실종아동 신원 파악에 도움을 준다.
- case 1)
- 실종아동 발견후 지문이 등록되어 있지 않아 신원 확인이 어려울 경우 실종아동의 얼굴 사진을 찍은 뒤, 얼굴 사진을 검사기에 입력.
- 얼굴이 사전에 등록되어 있을 경우 : 얼굴과 함게 저장되어 있는 이름, 나이, 보호자명, 보호자 연락처 등의 정보를 제공한다.
- 얼굴이 사전에 등록되어 있지 않을 경우 : 실종아동으로 등록된 사람들의 얼굴을 학습한 인공지능 모델이 사진속 얼굴과 유사한 실종아동 5명의 이름, 성별, 사진, 실종 발생일, 실종 당시 나이, 현재 나이, 신체적 특징, 실종 발생 장소에 대한 정보를 제공한다.
- 실종아동 발견후 지문이 등록되어 있지 않아 신원 확인이 어려울 경우 실종아동의 얼굴 사진을 찍은 뒤, 얼굴 사진을 검사기에 입력.
- case 2)
- 아동 보호 시설에서 살아온 사람들 중 본인이 실종아동이라는 사실도 모른채 살아가는 사람들이 존재하며 너무 어렸을 때 가족과 떨어져 실종아동이 되었기에 본인의 원래 이름을 모르고 있는 경우가 있다. 이러한 경우 이름을 이용한 실종아동 검색이 불가능 하기 때문에 얼굴 사진을 이용해 실종아동으로 등록되어 있는지 검사할 수 있다.
서비스 시나리오

서비스 경쟁력/차별화
경쟁(유사) 서비스 현황 ( 안전 Dream )

- 경찰청에서 기존 실종아동찾기 센터, 117학교·여성폭력 및 성매매피해자 긴급지원센터(117센터)등 관련 홈페이지를 통합한 서비스로 웹페이지와 앱으로 구현되어 있다.
- 앱의 설치 횟수는 100만회 이상으로 시장 규모가 굉장히 크다. 이는 '안전Dream'이 유일한 실종아동 전문 앱인 영향이 큰것으로 보인다.
- 평점은 리뷰 1000개, 3.7점으로 다소 낮다. 이는 휴대폰 인증, 정보 입력 등의 기능에서 많은 오류가 나기 때문인 것으로 보인다.
- 실종아동 검색의 경우 이름, 나이, 장소 등 한번에 하나의 정보만으로 검색을 하도록 되어있다.
- 앱내에서 지문 사전등록을 할 수 있는 서비스가 있지만 지문을 등록할 때 카메라로 지문을 인식시켜야 하기에 인식이 잘 안되는 문제점이 있다.
경쟁(유사) 서비스 대비 차별화 요소
- 집에서 간편하게 아이의 얼굴을 사전에 등록하여 실종 발생시 아이를 발견하였을 때 빠르게 신원 확인이 가능하다.
- 기존 '안전Dream' 앱에서 제공하는 핸드폰을 이용한 지문 사전등록 서비스의 경우 지문 자체가 잘 인식이 안되는 등 많은 오류가 발생하기 때문에 집에서 지문을 등록하기 어렵다.
- 앱으로 등록이 어려울 시 아이를 데리고 지구대, 파출소에 데려가 등록해야 하는 번거로움이 있다.
- 기존 서비스에는 없던 얼굴인식 인공지능을 이용한 실종아동 신원 검색이 가능하다.
- 얼굴인식을 통해 아이의 얼굴이 사전에 등록되어 있는지, 실종아동으로 등록되어 있는지 검사가 가능하다.
- 지문을 이용해 신원을 확인할 때 지문 인식 전용 기기가 필요하지만, 얼굴을 이용해 신원을 파악할 경우 별도의 기기 없이 핸드폰 카메라만으로 확인할 수 있다.
'A.아이(Project)' 카테고리의 다른 글
| [A.아이 Project] Ai모델 개발, 모델 구조 선택하기 (1) | 2023.03.23 |
|---|---|
| [A.아이 Project] Ai를 통한 미아찾기 모델 개발 (0) | 2023.03.16 |