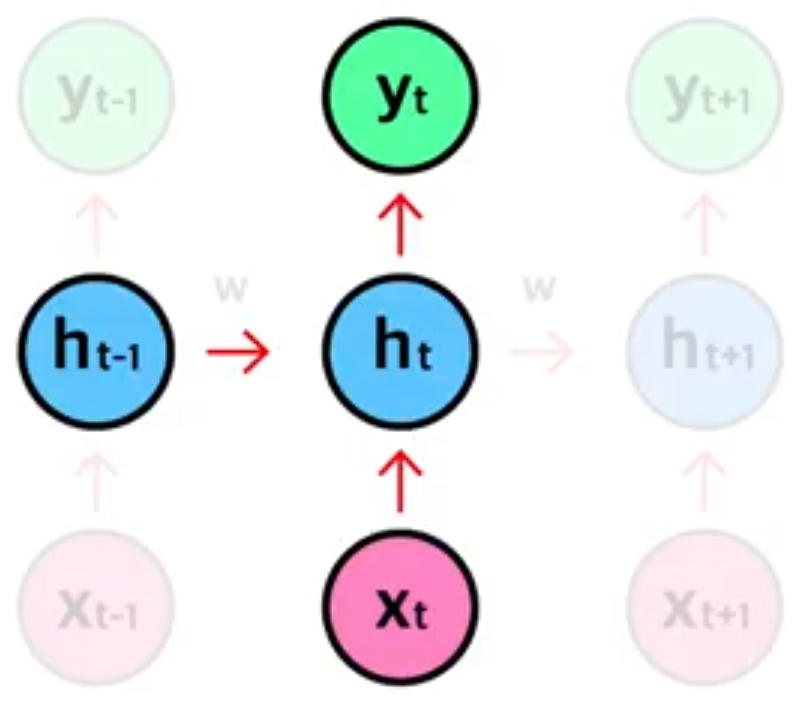
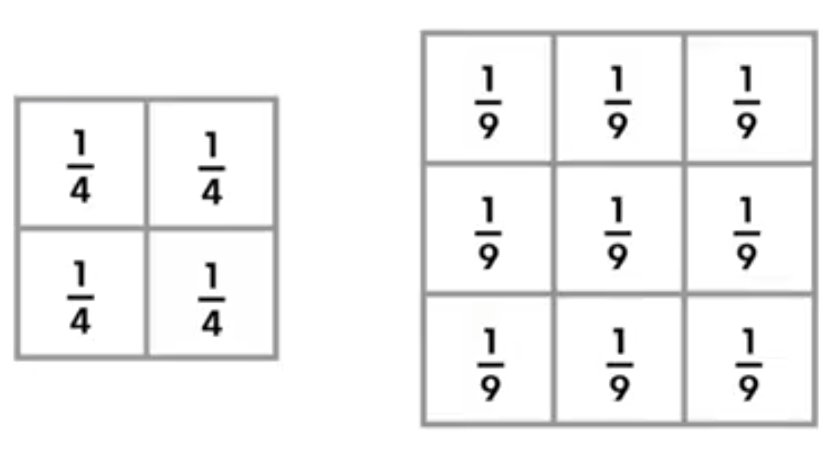
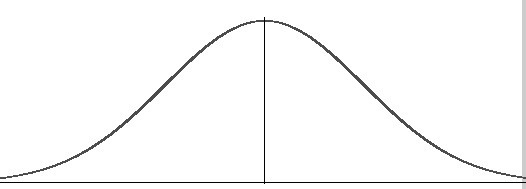
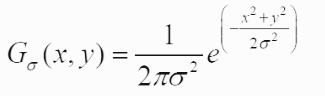화이트 모드로 보시길 권장합니다
[AI Friends School] 시리즈는 MicroShcool에서 진행하는 온라인 인공지능 학습 학교이다.
AI Friends School 강의 내용을 말하기 전, AI Friends School에선 어떠한 것을 배우는지 알아보자
AI Friends School이란?
AI Friends School은 인공지능 기술을 적용해 세상의 문제를 해결할 수 있는 시티즌 디벨로퍼로 성장하는 것을 목표로 한다.
-AI Friends School 온라인 과정 ( 36차시, 3개월 )-1. 인공지능 들어가기(1차시 ~ 10차시) 2. 인공지능·영상처리 이론(11차시 ~ 15차시) 3. 인공지능·영상처리 실습(16차시 ~ 23차시) 4. 인공지능·음성 / 자연어 처리 이론(24차시 ~ 28차시) 5. 인공지능·음성 / 자연어 처리 실습(29차시 ~ 36차시)
서비스 기획
서비스 기획
서비스를 지속적으로 운영, 수익을 발생시키기 위한 것이다.
' 고객은 누구인가? ', ' 어떠한 과제를 해결하는가? ', ' 무엇을 사용해 해결하는가? '를 명확히 설정하는 것이다.
아이디어 실현 가능성, 수익을 예상하여 시장을 확보하는 것이 중요하다.
프런트 엔드( Front-End ) 개발 : UI, UX 등을 개발하는 것을 뜻한다.
UI( User Interface ) : 디자인, 사용자가 서비스를 마주하는 것이다.
UX( User Experience ) : 사용자 경험, 사용자가 서비스를 사용하며 느끼는 경험이다.
백엔드( Back-End ) 개발 : 서버쪽 개발을 뜻한다. 데이터 저장&관리, 프런트엔드 필요 기능을 구현한다.
서비스에서 사용되는 인공지능 결정
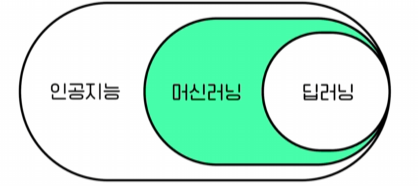
인공지능은 학습방법에 따라 용도, 성능이 결정된다.
서비스를 기획 후, 서비스에서 인공지능이 어떤 역할을 할지 파악, 역할에 따라 인공지능을 학습시켜야 한다.
( 인공지능의 종류와 관련된 글은 아래 글에서 확인할 수 있다. )
[AI Friends School] - [AI Friends School 4차시] 머신러닝(지도, 비지도, 강화)의 용어와 원리파악
[AI Friends School 4차시] 머신러닝(지도, 비지도, 강화)의 용어와 원리파악
화이트 모드로 보시길 권장합니다 [AI Friends School] 시리즈는 MicroShcool에서 진행하는 온라인 인공지능 학습 학교이다. AI Friends School 강의 내용을 말하기 전, AI Friends School에선 어떠한 것을 배우는
smcjungbumc.tistory.com
서비스의 목적, 데이터의 특성, 개발 기간, 학습 데이터 양 등을 고려해 학습 방법을 선택해야 한다.
개발 기간이 짧고, 데이터의 수가 적다면 머신러닝, 개발 기간이 길고, 데이터의 수가 많다면 딥러닝이 효율적이다.
개발 환경 종류
Pycharm
패키지 설치가 용이, 코드&함수 관리가 쉽다.
VSCode
Microsoft에서 제공하는 확장 프로그램을 쉽게 사용 가능하다.
다양한 코드 분석 창들이 있다.
Jupyter Notebook
사용자가 정한 단위를 기준으로 코드를 실행하여 결과를 확인할 수 있다.
Colab
개발 환경을 추가적으로 설정할 필요가 없다.
Anaconda
프로젝트별로 라이브러리를 나눠 버전을 관리할 수 있다.
Git
프로젝트, 코드의 버전관리가 가능하다.
branch를 통해 여러 사람과 협업이 가능하다.
학습 데이터
학습 데이터
인공지능을 학습시키는 데이터를 의미한다.
인공지능 모델을 개발할 때, 학습 데이터를 준비하는 과정이 많은 시간을 차지한다.
Kaggle, 공공데이터 포털, AI hub 등 학습 데이터를 제공하는 사이트에서 데이터터를 수집한다.
직접 데이터를 수집할 수도 있다.
데이터를 준비한 후, 각 데이터 항목에 맞지 않는 값, 빈 값의 유무, 항목별 데이터 수가 일정한지 검사해야 한다.
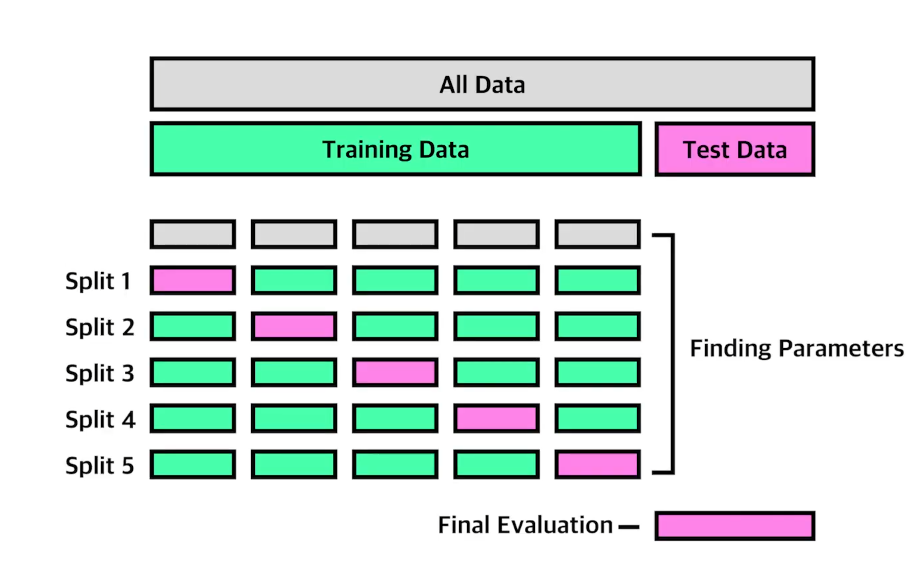
모델을 학습시킬 데이터셋이 준비되었다면 학습 데이터, 테스트 데이터로 나누어야 한다.
가공 :
수집된 데이터를 인공지능이 쉽게 이해, 학습할 수 있도록 하는 과정을 뜻한다.
Python의 Pandas, Numpy, Matplotlib 등의 라이브러리를 통해 데이터를 가공한다.
이미지 데이터의 경우 라벨링 툴을 이용해 데이터를 가공한다.

AI 학습
AI 프레임 워크
Tensorflow, Keras, Torch 등의 딥러닝 프레임 워크를 사용한다.
인공지능 개발의 경우 주로 Tensorflow, Torch를 사용한다.
개발 환경, 상황에 따라 프레임 워크를 선택해 학습을 해야 한다.
프레임워크 : 프레임워크의 룰을 의무적으로 따르며 개발
라이브러리 : 개발하며 선택에 따라 라이브러리를 사용
Torch : Numpy, Python과 코드가 비슷하며 디버깅(오류 수정)이 쉽다.
Tensorflow : 학습이 빠르고 인공지능의 학습 과정을 시각화하는 Tensorboard를 사용할 수 있다.
Keras : Tensorflow 내부에 속해있는 것으로, 모델&학습 데이터를 제공, 학습을 단순화하기에 사용이 쉽다.
AI 모델 평가
1. 모델은 전반적으로 얼마나 정확한가?
2. 모델은 여러 시나리오에서 예상대로 작동하는가?
3. 예외적인 상황을 전부 고려했는가?
위 기준에 따라 테스트 세트를 이용해 모델을 점검한다.
수치로 확인 가능한 부분은 여러 도구를 이용해 점검이 가능하다.
Tensorflow의 경우 학습 과정에서 loss, accuracy(정확도)를 확인 가능하며, Tensoboard를 통해 학습 과정을 모니터링할 수 있다.
도구를 통해 과소적합, 과대적합의 상황을 판별하고 이를 기반으로 다시 학습을 진행한다.
AI 배포
AI 배포
모델 학습이 완료되면 서비스 환경에 맞춰 코드를 적용하며, 환경은 하드웨어에 따라 달라지게 된다.
임베디드, 서버, 모바일, 데스크탑의 하드웨어가 있으며 하드웨어에 설치된 OS에 맞춰 코드, 모델을 적용해야 한다.
각각의 환경에 맞는 모델, 코드를 적용하여 시스템이 서로 상호 작용할 수 있도록 하는 것은 중요하다.
위 과정을 통해 서비스 점검이 끝나게 되면 모델, 서비스를 배포하게 된다.
지속적인 모니터링을 통해 모델의 동작에 문제가 없는지 확인해야 한다.
문제가 발생하게 될 경우 AI학습 단계로 돌아가 다시 학습을 진행해야 한다.
파인 튜닝( Fine-Tuning ) :
기존 모델을 활용해 수집한 데이터로 학습하는 것을 의미한다.
서비스를 운영하며 사용자들의 데이터를 수집해 더 나은 성능을 위해 모델을 재학습시키기도 한다.
모델의 성능이 나빠질 수도 있기에 학습시키기 전, 모델을 저장하는 롤백 과정을 진행하기도 한다.
MLOPs
MLOPs란?
데이터가 쌓이고, 지속적으로 변화하는 서비스 환경에 맞춰 개발하는 과정을 의미한다.

다음 차시에는 인공지능의 영상 처리 기법&전처리 방법에 대해 배운다.
'AI Friends School' 카테고리의 다른 글
| [AI Friends School 10차시] RNN이란? (1) | 2023.01.27 |
|---|---|
| [AI Friends School 9차시] CNN이란? ( 평균값 필터, 가우시안 필터 ) (1) | 2023.01.26 |
| [AI Friends School 8차시] 이미지 데이터의 이해 (1) | 2023.01.19 |