화이트 모드로 보시길 권장합니다
[AI Friends School] 시리즈는 MicroShcool에서 진행하는 온라인 인공지능 학습 학교이다.
AI Friends School 강의 내용을 말하기 전, AI Friends School에선 어떠한 것을 배우는지 알아보자
AI Friends School이란?
AI Friends School은 인공지능 기술을 적용해 세상의 문제를 해결할 수 있는 시티즌 디벨로퍼로 성장하는 것을 목표로 한다.
-AI Friends School 온라인 과정 ( 36차시, 3개월 )-1. 인공지능 들어가기(1차시 ~ 10차시) 2. 인공지능·영상처리 이론(11차시 ~ 15차시) 3. 인공지능·영상처리 실습(16차시 ~ 23차시) 4. 인공지능·음성 / 자연어 처리 이론(24차시 ~ 28차시) 5. 인공지능·음성 / 자연어 처리 실습(29차시 ~ 36차시)
모델이란?
모델
특정 유형의 규칙을 인식하게 훈련된 프로그램 파일이다.
모델이 학습되었다는 것은 컴퓨터 스스로 데이터 규칙을 찾는 기술을 갖고 있다는 뜻이다.
사용 이유 :
빠르게 데이터를 학습하여 높은 정확도로 예측, 판단이 가능하기 때문이다.
모델을 만들기 위한 준비물 :
학습시키고자 하는 데이터가 필요하다.
( ex. 사과 인식 모델 => 여러 사과 사진, 엑스레이 사진을 통해 질병 판단 모델 => 여러 환자들의 다양한 엑스레이 사진 )
데이터 세트와 테스트 세트
데이터 세트
모델을 학습시키기 위해 수집된 자료들을 뜻한다.
데이터 세트는 ' 트레이닝 세트(Training Set; 학습 데이터) ', ' 테스트 세트(Test Set; 점검 데이터) '로 나뉜다.
두 세트의 비율은 보통 8:2로 트레이닝 세트의 비율이 높다.
트레이닝 세트( Training Set ) :
모델을 학습시키는 데이터 세트이다.
테스트 세트( Test Set ) :
학습시킨 모델을 점검해 보기 위한 데이터 세트이다.
데이터 세트를 나누는 이유 :
시험을 보기전 모의 고사를 통해 실력을 점검 하듯, 모아진 데이터가 학습이 잘 되었는지 확인하기 위해서이다.
모델이 트레이닝 세트를 이용해 학습하고, 모델이 새로운 데이터를 접해도 잘 예측하는지 테스트 세트를 이용해 점검한다.
과대적합과 과소적합
과대적합과 과소적합
머신러닝을 할 때 모델의 성능을 낮추는 문제이다.
과대적합( Over Fitting )
모델이 훈련 세트에 과하게 적합한 상태가 되어 일반성이 떨어지는 현상이다.
트레이닝 세트에만 정확성을 보이고, 그 외 새로운 데이터에서는 낮은 정확도를 보이는 모델이다.
데이터 세트가 충분치 않을 경우 과대적합의 원인이 된다.
교차검증( Cross Validation ) :
데이터 수가 적을 경우 과대적합을 해결하기 위한 방법이다.
데이터를 여러번 반복해서 나누어 모델의 학습을 검증하는 방법이다.

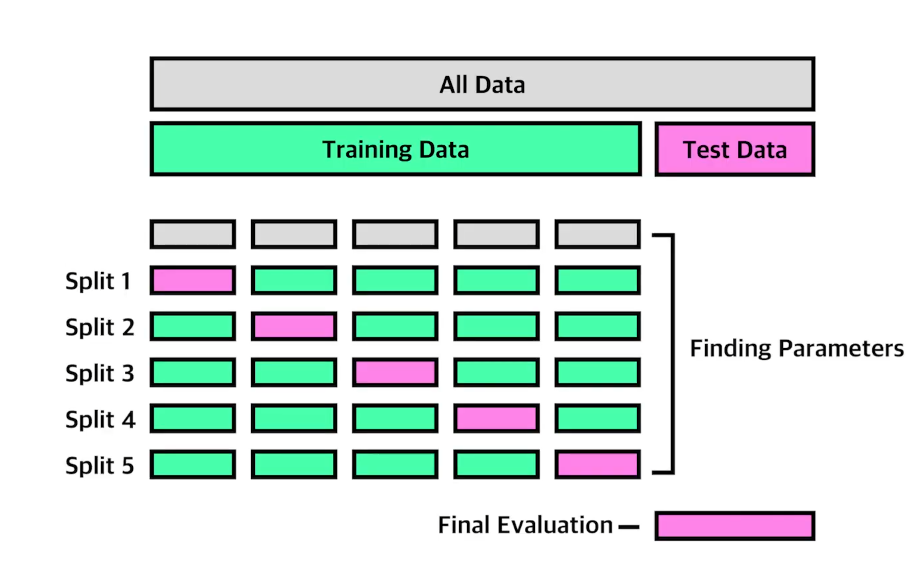
하나의 데이터 세트를 트레이닝 세트와 테스트 세트로 여러번 나누었을 경우의 평균적인 성능을 계산해 볼 경우,
한번 나누어 학습하는 것에 비해 좀더 일반화( 새로운 데이터에 잘 대응 )된 성능을 얻을 수 있다.
과소적합( Under Fitting )
모델이 훈련 세트의 규칙을 제대로 찾지 못해 테스트 세트에 대한 정확도가 모두 낮은 경우이다.
모델의 복잡도가 낮을(복잡한 문제를 몇개의 특정 요소만을 가지고 해결하려는 것을 의미) 경우 나타난다.
해결 방법 :
조금 더 복잡한 모델을 이용하여 적합한 규칙을 찾아낼 수 있는 모델을 만들어야 한다.
머신러닝
머신러닝은 지도학습, 비지도학습, 강화학습 3가지로 나뉜다.
지도학습에서 회귀분석의 경우 변수 관계를 파악하여 예측하고, 분류는 데이터가 어떤 종류에 속하는지 판단한다.
각각의 방법은 그 목적이 다르기에 각 모델을 평가하는 지표가 다를 수 밖에 없다.



회귀 모델

회귀 모델은 연속성 있는 데이터의 예측값을 얻는 것에 목표를 두고 있다.
예측값의 정확도는 회귀 모델에게 있어 중요한 성능 평가 지표가 된다
실제 값과 모델이 예측한 값의 차이를 오차, 손실이라 부른다.
오차가 0에 가까울 수록 정확한 예측을 한 것으로, 모델의 성능이 좋다고 말할 수 있다.
손실함수( Loss Funtion ) :
회귀 모델의 오차를 계산하는 함수이다.
대표적으로 ' 평균절대오차(Mean Absolute Error; MAE) ', ' 평균제곱오차(Mean Square Error; MSE) '가 있다.
회귀 모델 평가
평균절대오차( Mean Absolute Error; MAE )
실제값과 예측값 차이의 절대값을 평균하는 방법이다.

비교적 간단한 방법으로 많이 사용되며, 0에 가까울 수록 좋은 모델이다.
절대값 만을 적용하기에, 오차 정도를 가장 직관적으로 알 수 있는 지표이지만, 오차의 방향성을 알 수 없다는 단점이 있다.

평균제곱오차( Mean Square Error; MSE )
실제값과 예측값의 차이를 제곱하여 평균을 내는 방법이다.
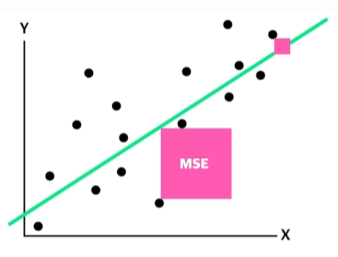
제곱을 하는 이유는 음수를 없애기 위해서이다.
오차가 -5와 +5가 있을 경우 이의 합이 0이 되는 것을 방지하기 위해서 이다.
오차값들이 제곱되기에, 회귀값 또는 아웃라이어(outlier)들을 상대적으로 더 크게 확대시킨다는 특징이 있다.
값이 0에 가까울 수록 좋은 모델이다.

분류 모델 평가
분류 모델의 성능을 평가하는 지표
분류 모델이 예측을 수행하며 긍정(Positive)했는지, 부정(Nagative)했는지, 사실(True)인지, 거짓(False)인지에 따라
네 개의 경우의 수로 구분하여 표로 나타낼 수 있는데, 이를 오차행렬(Confusion Matrix)이라 한다.
오차행렬은 모델이 예측을 수행한 분류 결과를 실제 값과 비교하여 정리해 주는 표이다.
가장 좋은 모델은 정확도, 정밀도를 모두 잡은 모델이다.
( 정확도와 정밀도 모두 높은 모델은 정확히 목표한 대로의 결과를 낼 수 있다. )

오차행렬
오차행렬( Confusion Matrix ) 표 분석 :
코로나를 예로 들 경우,
모델이 환자가 코로나 양성이라 예측하고, 실제로 환자가 코로나 양성일 경우 ' True Positive; TP '의 케이스가 된다.

모델이 환자가 코로나 음성이라 예측하고, 실제로 환자가 코로나 음성일 경우 ' True Negative; TN '의 케이스가 된다.

위에 두 경우 모두 모델이 분류를 잘 했기 때문에 앞에 True가 붙으며 모델이 분류를 잘 못했을 경우 앞에 False가 붙는다.
모델이 환자가 코로나 음성일 것이라 예측했지만, 실제로 양성일 경우 잘못된 예측으로 ' False Negative; FN '에 해당한다.

오차행렬( Confusion Matrix )의 효과 :
모델의 예측값과 실제값과의 관계를 표로 정리할 경우 정확도, 정밀도, 재현율이라는 수치를 통해 결과에 대한 추가적인
분석이 가능하며 이 수치들은 인공자능 성능 평가를 위한 지표로써 구체적인 의미를 갖는다.

정확도( Accuracy ) :
전체 데이터 중에서 모델이 정확하게 예측한 것의 비율을 의미한다.

정확도를 분류 모델의 평가 지표로 사용할 때에는 주의할 점이 있다.

코로나 환자 10명중 9명이 음성이고, 한명이 양성일 경우,
모델이 무조건 음성이라 예측하기만 해도 모델의 정확도는 90%가 된다.
이 수치로만 본다면 굉장히 정확한 예측을 하는 모델로 착각할 수 있다.
때문에 위와 같이 불균형한 데이터는 적합한 평가 지표가 될 수 없다.
정밀도( Precision ) :
모델이 Positive라고 예측한 것 중에서 정답의 비율, 즉 실제로도 Positive인 경우의 비율을 의미한다.

재현율( Recall ) :
통계학에서는 민감도(Sensitivity)라는 용도로도 사용된다.
실제로 True인 것중에서 모델이 True라고 예측한 것의 비율을 의미한다.

다음 차시에는 인공지능을 설계하는데 필요한 수학 개념에 대해 배운다.
'AI Friends School' 카테고리의 다른 글
| [AI Friends School 6차시] 인공지능 수학 (2) | 2023.01.10 |
|---|---|
| [AI Friends School 4차시] 머신러닝(지도, 비지도, 강화)의 용어와 원리파악 (0) | 2022.12.05 |
| [AI Friends School 3차시] 인공지능의 범주와 개념 (1) | 2022.11.28 |